
Basic Document Representation
Difference between bag of words and TFIDF model - An Example
We all know that using TF-IDF values instead of bag of words is a better way of representing documents. Using TF-IDF basically reduces the weight of very common words that don’t really help us differentiate documents. Common words like ‘and’ , ‘the’ , ‘very’ , ‘an’ etc. are present in all the documents irrespective of the theme of the document.
Let’s look at an example and see the difference. The Jupyter notebook can be found here.
I used the People Wiki dataset for the analysis which can be found here.
I applied the below 3 steps to the dataset to compare the performance of bag-of-words vs TFIDF -
- Convert the dataset’s
textcolumn into bag-of-words / TFIDF - Build a KNN model using the generated features
- Find top 10 neighbors of ‘Joe Biden’
Results with the bag-of-words model
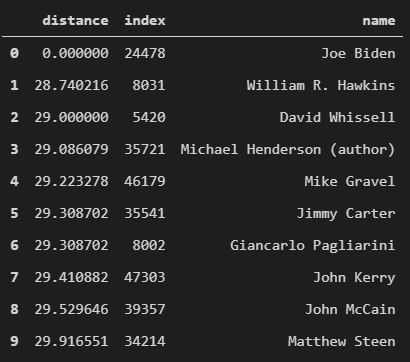
As you can see, 3 neighbors are William R. Hawkins(don’t know who that is), David Whissell(Canadian Politician) and Michael Henderson (well, author). I was hoping to see more US presidents or people closely related to Joe Biden as top matches. Now let’s look at top words with highest values in the bag-of-words representation of Joe Biden’s wiki article -

Clearly, the words that have the highest weight are very common words, and these words can be found in any article - related or unrelated to US presidents.
Results with TFIDF model
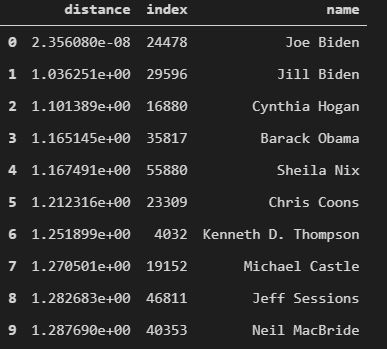
Ah, now we see some people who are actually closer to Joe Biden. First one is Jill Biden which makes sense because she is the First Lady. Next, Cynthia Hogan - she served as Counsel to Joe Biden when he was VP during Obama administration from 2009-2013. Finally, we have Barack Obama and it doesn’t need further explanation. Okay, now we have some sensible neighbors. Let’s look at top words with highest values in the TFIDF representation of Joe Biden’s wiki article -
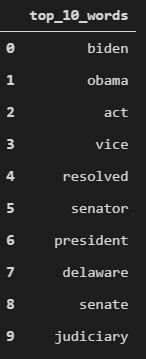
Notice that none of the words above are common words and that’s what we wanted!
Conclusion
When we compared Joe Biden’s neighbors from the bag-of-words model and TFIDF model, we clearly saw that TFIDF model came up with more relevant neighbors. When we compared the top 10 words from both the models, we indeed saw that TFIDF chose words that were more specific to an article on a US president as opposed to any other article - say an article on sports on about a musician or a band.